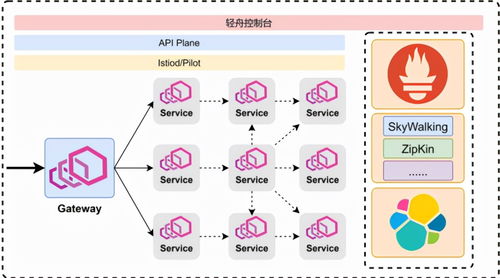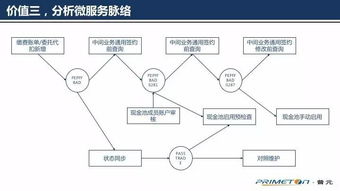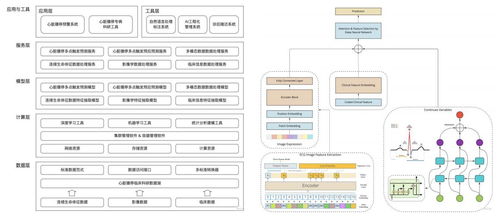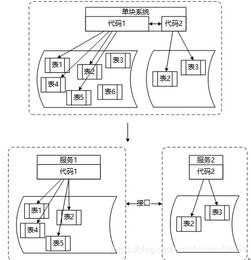
在微服务架构中,数据处理服务的建模是确保系统可扩展性、一致性和可维护性的关键环节。随着业务逻辑的分散和数据所有权的去中心化,如何有效处理服务间的数据交互、转换与持久化成为核心挑战。本文将探讨微服务建模中数据处理服务的构建原则、常见模式及最佳实践。
一、数据处理服务的核心职责
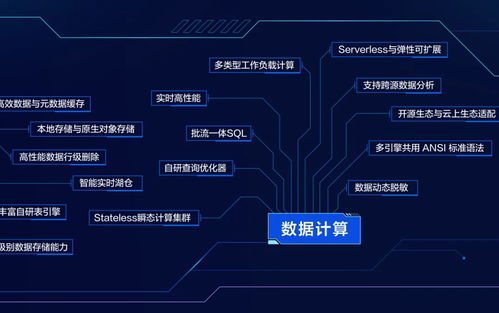
数据处理服务主要负责数据的提取、转换、加载(ETL)、聚合与同步,旨在满足特定业务场景的需求。其核心职责包括:
- 数据转换与标准化:将不同服务的数据格式统一为业务所需的模型,确保跨服务数据一致性。
- 数据聚合与计算:整合多个服务的分散数据,生成综合视图(如报表、分析结果)。
- 异步数据处理:通过消息队列或事件驱动机制,处理高吞吐量或延迟敏感的数据流。
- 数据缓存与优化:为高频查询提供缓存层,减轻源服务压力并提升响应速度。
二、建模关键原则
- 单一职责与界限上下文:每个数据处理服务应聚焦于特定业务领域(如订单分析、用户行为跟踪),避免功能臃肿。明确其数据输入输出的界限,减少跨域耦合。
- 事件驱动与异步通信:优先采用事件驱动架构(如发布/订阅模式),使数据处理服务能够独立响应数据变更事件,增强系统解耦性和弹性。
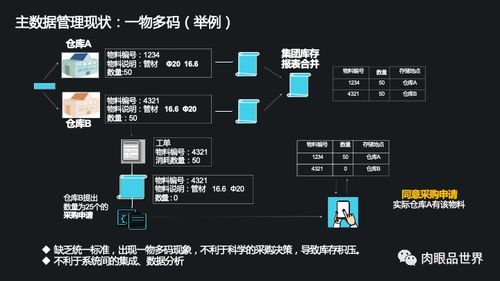
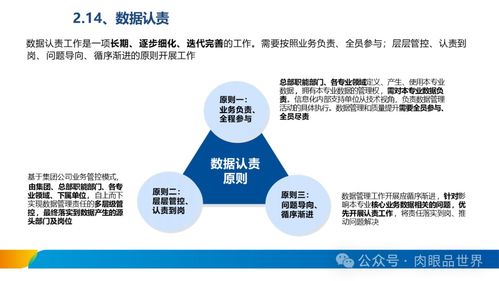
- 数据所有权与去中心化:坚持“谁产生,谁拥有”原则,源服务保留主数据所有权;数据处理服务仅持有衍生数据副本,避免直接修改源数据。
- 容错与可观测性:设计重试机制、死信队列和监控指标(如处理延迟、错误率),确保数据管道的可靠性。
三、常见模式与场景应用
- 聚合器模式(Aggregator):适用于需要合并多个微服务数据的场景,如仪表盘服务从订单、库存和物流服务拉取数据后生成综合视图。可通过API组合或异步事件收集实现。
- CQRS(命令查询职责分离)模式:将数据写入(命令)与读取(查询)分离。数据处理服务可作为查询端,从事件日志中构建优化后的读模型,支持复杂查询而不影响核心业务逻辑。
- 事件溯源(Event Sourcing)模式:将数据变更记录为事件序列,数据处理服务订阅这些事件以构建当前状态或历史分析,适用于审计跟踪和实时分析场景。
- 数据管道模式:通过流水线式处理(如Kafka Streams、Apache Flink)实现实时数据清洗、转换与加载,常用于大数据分析和实时监控。
四、挑战与应对策略
- 数据一致性问题:在最终一致性模型中,通过版本控制、事件时序保证和补偿事务(如Saga模式)处理异常情况。
- 数据冗余与存储成本:合理设置数据生命周期策略(如TTL自动清理),采用列式存储或压缩技术优化存储效率。
- 跨服务数据依赖:通过契约测试和API版本管理确保接口兼容性;使用数据血缘工具跟踪依赖关系,降低变更风险。
- 性能瓶颈:采用分片、并行处理和读写分离策略提升吞吐量;对于复杂计算,可引入批处理或增量计算优化资源使用。
五、实践建议
- 渐进式建模:从核心业务场景出发,优先构建最小可行数据处理服务,再逐步扩展功能。
- 基础设施即代码:利用容器化(Docker)和编排工具(Kubernetes)实现服务的自动化部署与伸缩。
- 测试驱动开发:针对数据转换逻辑编写单元测试,并通过集成测试验证跨服务数据流。
- 文档与治理:明确记录数据流的来源、格式和用途,建立团队间的数据契约协议。
数据处理服务在微服务生态中扮演着“粘合剂”角色,其建模质量直接影响系统的整体效能。通过遵循领域驱动设计原则、选择适配模式并持续优化,团队能够构建出高内聚、低耦合且稳健的数据处理体系,支撑业务的快速迭代与创新。